VPC Lattice: l’ennesima service mesh o un game changer?
12 Aprile 2024 - 4 min. read
Damiano Giorgi
DevOps Engineer



L’ETL rappresenta uno step fondamentale in un processo di Machine Learning in quanto è il trampolino di lancio su cui si basa tutto il set di dati per la definizione del modello, per questo i data scientist e gli esperti MLOps pianificano attentamente i job e le pipeline per gestire l'estrazione dei dati dai database, spesso di natura diversa, pulendo e normalizzando i dati ed infine, generando un data lakeper migliorare ulteriormente i dati durante il processo di indagine.
Di solito, questo processo prevede diversi passaggi, il coordinamento della loro esecuzione, l'accesso a diversi database con diverse tecnologie, la preparazione di molti script, la conoscenza di diversi linguaggi per interrogare i dati rilevanti e così via.
Prendersi cura di tutti questi passaggi è un compito ardito e richiede molta esperienza e, naturalmente, tempo, minando l'efficienza dell'intero progetto che si deve gestire.
AWS, che sta progredendo molto rapidamente negli ultimi due anni nello sviluppo di strumenti e servizi per aiutare nelle attività di machine learning, questa volta ci porta un altro importante servizio in soccorso: AWS Elastic Views.
AWS Elastic Views consente a un utente di richiedere dati da diverse fonti in modo completamente indipendente dalla loro natura, di eseguire query per i dati in un linguaggio compatibile con SQL e di inviare tutti i dati interrogati a una destinazione, tipicamente S3 o un'altra destinazione dati, ed infine a produrre un data lake con cui lavorare.
Alcuni dei principali vantaggi sono:
Lo scopo di questo articolo è guidare il lettore nell'esplorazione di alcuni dei fattori chiave che rendono questo servizio qualcosa di cui essere definitivamente consapevoli nei propri progetti di Machine Learning.
Esploreremo in profondità ciò che è in grado di fare AWS Elastic Views, considerando però che è ancora in fase beta, quindi si dovrà richiedere l'accesso ad AWS per l'anteprima.
Cominciamo!
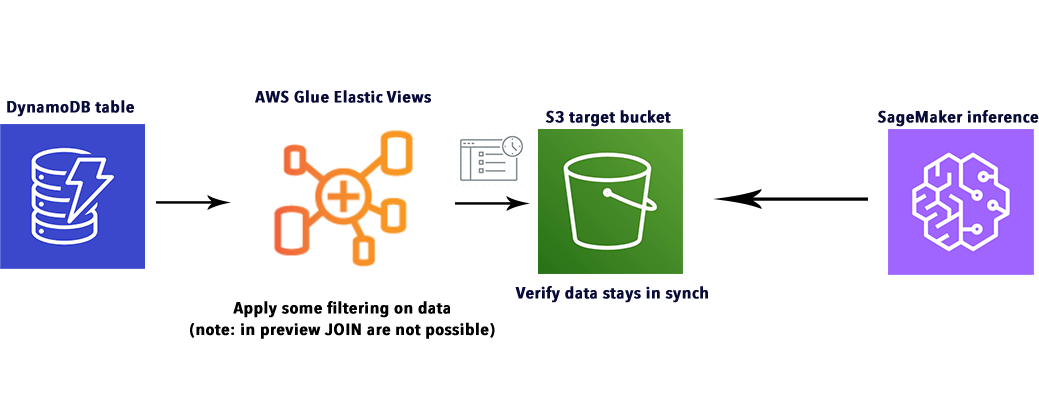
Cominciamo il nostro viaggio capendo che cos’è AWS Glue Elastic Views, e come funziona. Per prima cosa, diamo uno sguardo allo schema fornito da AWS:
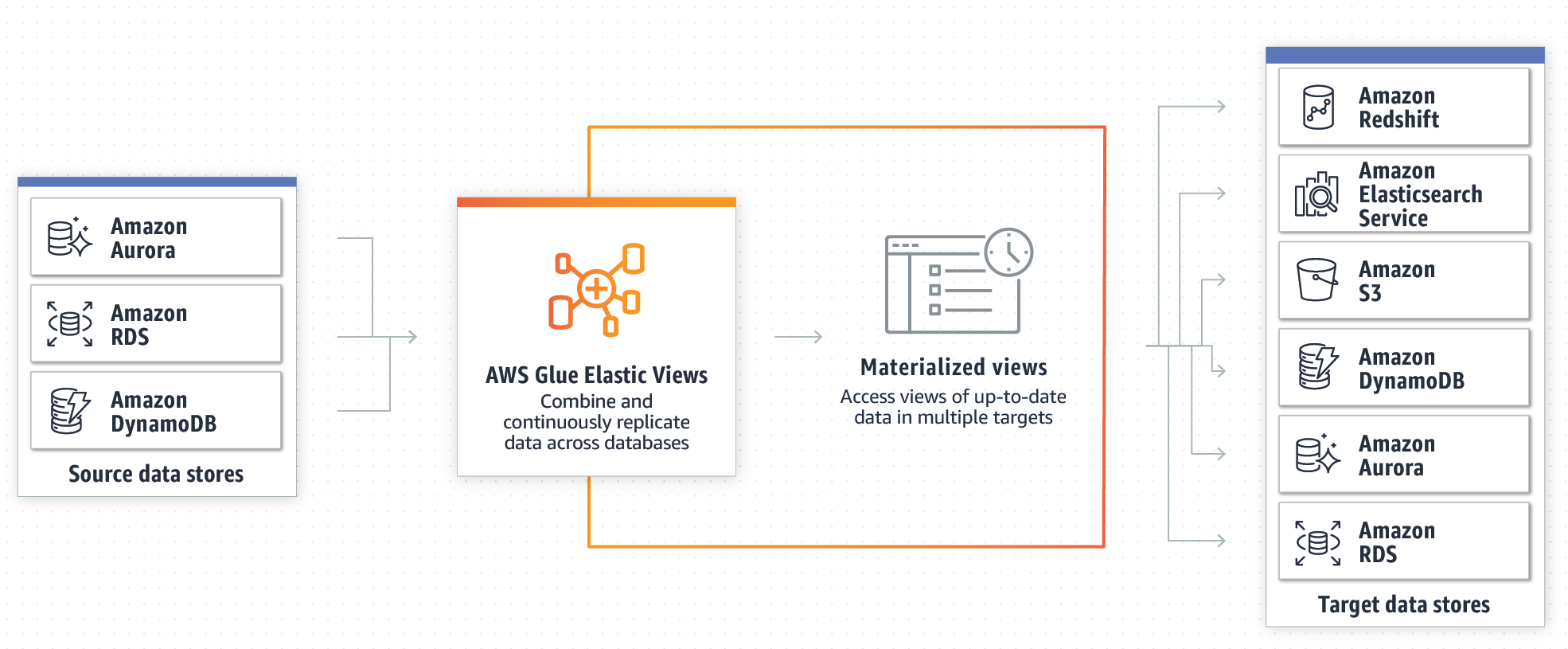
Come mostrato nell'immagine, il punto focale di questo servizio è rappresentato dalla Materialized View, che è un sistema per astrarre il set di dati da qualsiasi tipo di sorgente: ad esempio Amazon Aurora, RDS o DynamoDB. Ciò consente di mantenere le informazioni sincronizzate senza l'uso effettivo di un Glue Crawler, come ci saremmo aspetti dai nostri altri articoli sui workload ETL (qui e qui alcuni esempi).
Ma diamo un'occhiata in dettaglio alle caratteristiche principali e come possono essere utili.
AWS Glue Elastic Views consente a uno sviluppatore di creare viste materializzate su diverse origini di dati, utilizzando query SQL per aggregare i dati. AWS Glue Elastic Views attualmente supporta Amazon DynamoDB, Redshift, S3 e Elasticsearch Service. Inoltre, AWS ha in programma di aggiungere ancora più origini di dati in futuro.
AWS Glue Elastic Views gestisce per noi il lavoro più pesante di copia e aggregazione dei dati da tutte le origini dati fino agli archivi di destinazione, senza dover scrivere codice personalizzato o utilizzare strumenti ETL e linguaggi di programmazione complessi o sconosciuti, con un effetto benefico sia sul tempo che sull'efficienza del progetto. AWS Glue Elastic Views riduce il tempo necessario per combinare e replicare i dati negli archivi dati da mesi a minuti, secondo AWS.
Mantenere i dati sincronizzati di solito richiede la creazione e la manutenzione di crawler, AWS Glue Elastic Views, invece, monitora continuamente le modifiche ai dati negli archivi dati iniziali e, quando si verifica una modifica, Elastic Views aggiorna automaticamente le destinazioni. Ciò garantisce che le applicazioni che accedono ai dati utilizzando Elastic Views dispongano sempre dei dati più aggiornati.
AWS Glue Elastic Views avvisa in modo proattivo gli sviluppatori quando viene apportata una modifica al modello di dati in uno degli archivi dati di origine, in modo che possano aggiornare le loro visualizzazioni per adattarsi a questa modifica velocemente.
AWS Glue Elastic Views è completamente serverless e aumenta o diminuisce automaticamente la propria capacità per adattarsi automaticamente ai carichi di lavoro. Non c'è hardware o software da gestire e, come sempre, un utente paga solo per le risorse che utilizza.
Essendo un servizio ancora in beta è necessario registrarsi per la preview gratuita: per farlo, è sufficiente andare a questo indirizzo e registrarsi, compilando l’apposito form.
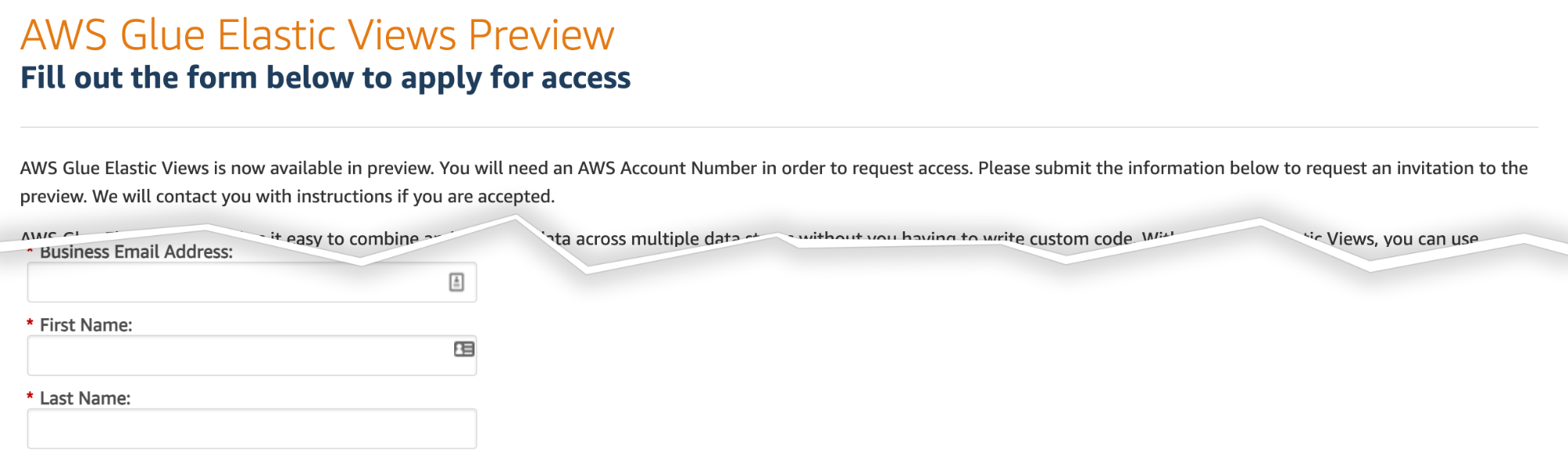
Verranno richiesti i dettagli personali e aziendali, nonché un'introduzione di base al problema che si desidera risolvere utilizzando AWS Glue Elastic Views. È bene Assicurarsi di fornire motivazioni ragionevoli, poiché casi d'uso interessanti aumentano le possibilità di essere selezionati per l'anteprima.
Di solito, AWS risponde entro una settimana e se idoneo per l'anteprima, il seguente messaggio verrà inviato alla propria email.

Dopo essersi registrati, per accedere a Glue Elastic View è necessario cliccare sul link fornito nella mail.
Ora siamo pronti per iniziare il nostro primo workload ETL con Elastic View, invece di utilizzare script Spark standard o Glue Crawler.
Il modo migliore per capire le possibilità di questo servizio è metterci alla prova con esso. Quindi abbiamo deciso di creare un semplice caso d'uso per presentare come potrebbe essere utilizzato per semplificare i propri workload ETL.
L'idea di base è popolare una tabella DynamoDB con alcuni dati di test ottenuti da fonti di dati gratuite. Vogliamo estrarre e manipolare i dati da questa tabella per dimostrare come Glue Elastic Views può aggiungere efficacemente funzionalità ETL a DynamoDB, che è storicamente un po' debole su questo aspetto.
Quindi vogliamo inviare questi dati a S3 e verificare che sia possibile aggiornarli in tempo reale per riflettere i cambiamenti, dimostrando come Glue Elastic Views può accelerare efficacemente il processo di indagine di una pipeline di Machine Learning.
Nota: al momento della scrittura di questo articolo, sfortunatamente, l'operazione JOIN non è supportata per PartiQL in AWS Glue Elastic Views, quindi abbiamo optato per testare alcune operazioni matematiche e logiche, oltre a convalidare tutti i passaggi per sincronizzare la tabella DynamoDB con il bucket S3.
Per il nostro esempio, abbiamo deciso di utilizzare un semplice set di dati sugli avvistamenti UFO. Vogliamo mettere questo file CSV in una tabella DynamoDB, come detto prima, e applicare alcune operazioni di filtraggio sui campi di latitudine e longitudine, o anche città. Il risultato verrà utilizzato per rispondere alla seguente domanda di esempio: "In che modo gli avvistamenti UFO variano a seconda delle diverse zone?".
Questo è, ovviamente, solo un semplice esempio, non ha implicazioni pratiche a parte dimostrare alcune funzionalità di AWS Glue Elastic Views.
Vogliamo creare la tabella per DynamoDB, e per fare questo, abbiamo definito un semplice script, in SageMaker Studio, che si sobbarchi l’operazione per noi.

Fondamentalmente andiamo a leggere i dati dal file CSV usando Pandas, convertiamo le righe in JSON, ma prima di farlo, aggiungiamo anche una colonna "hash" chiamata id, perché DynamoDB ha bisogno di una chiave primaria per ogni item.
for record in json_list:
if record['longitude '] and record['latitude']:
record['id'] = sha256(str(record).encode()).hexdigest()Il set di dati sugli UFO presentava anche alcuni problemi che dovevano essere risolti: l’header "longitudine" aveva degli spazi da rimuovere e le colonne di latitudine e longitudine dovevano essere convertite in formato stringa rimuovendo le voci NaN.
Infine, abbiamo utilizzato boto3 per creare una tabella corrispondente al CSV.
dynamodb = boto3.resource('dynamodb')table = dynamodb.Table('article_ufo_sightings')with table.batch_writer() as batch:...batch.put_item(Item=record)Il codice completo può essere esplorato qui.
Nota: avremmo potuto utilizzare AWS Glue anche per questa attività, inserendo il file CSV in un bucket S3 di origine, utilizzando poi Glue Crawler per importare i dati, ma poiché abbiamo già trattato i lavori ETL con questo servizio in altri articoli,abbiamo optato per una soluzione più semplice non essendo questo il fulcro dell'esempio.
Siamo semplicemente andati alla console DynamoDB, abbiamo cliccato su "create table" e abbiamo utilizzato le semplici impostazioni segnate in immagine. Una nota però: applichiamo la modalità di capacità on-demand per velocizzare la generazione della tabella.

Aggiungiamo id come chiave primaria per la tabella UFO sightings
Prima di generare la vista, dovevamo aggiungere la tabella DynamoDB come sorgente in AWS Glue Elastic Views; per farlo, siamo andati alla console principale, abbiamo selezionato “Tables” a sinistra e cliccato su “Create Table”. Quindi abbiamo selezionato la nuova tabella DynamoDB, generata nei passaggi precedenti.

Il passaggio successivo è stato applicare alcuni filtri per creare il nostro set di dati di destinazione finale, dipendente dalla vista.
Andando sulla scheda "Views" sul lato sinistro della console ne abbiamo creata una nuova. Qui ci è stata presentata la possibilità di scrivere codice PartiQL personalizzato: esattamente quello che volevamo!
Abbiamo aggiunto il seguente codice nell'editor per abilitare la nostra vista materializzata:
SELECT id, Latitude, Longitude FROM article_ufo_sightings.article_ufo_sightingsAbbiamo anche dovuto scrivere tutti gli attributi che volevamo esportare nei file di parquet di destinazione (sembra che AWS Glue Elastic Views generi batch di file di parquet nella directory di output).
Come il lettore può osservare dal codice sopra, abbiamo evitato di richiedere apposta informazioni utili: volevamo mostrare che è possibile modificare la vista in tempo reale dopo che la materialized view è stata creata.
Al momento della scrittura di questo articolo, S3 è una delle tre opzioni disponibili come target, insieme a ElasticSearch e Redshift. Nel nostro caso S3 è la destinazione ideale, in quanto vogliamo che il set di dati finale venga consumato da SageMaker.
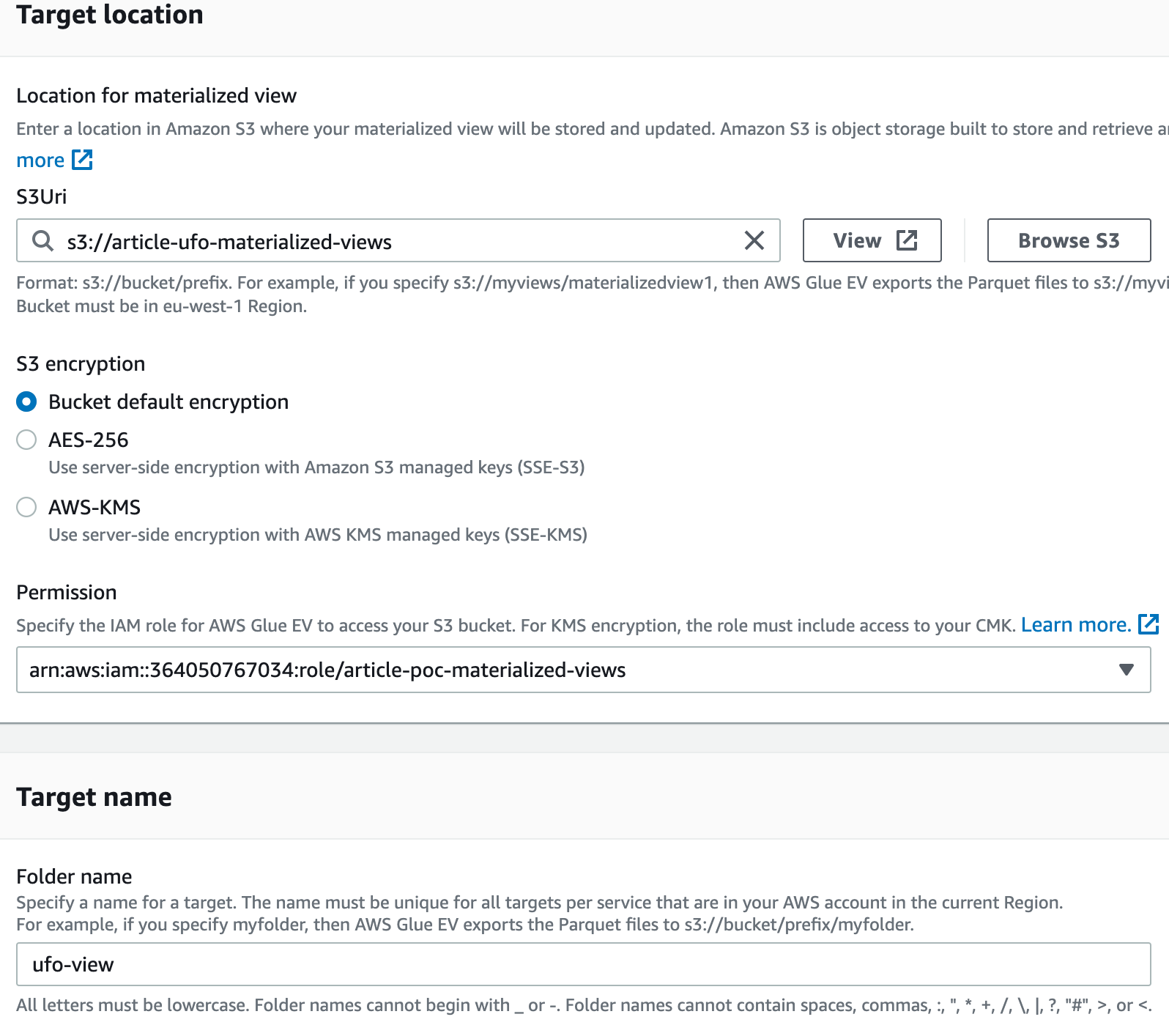
Siamo andati dentro la View e abbiamo cliccato su “Materialized View”, quindi abbiamo selezionato “Glue EV” come supporto per sbloccare “S3” come target: lì abbiamo aggiunto il bucket “article-ufo-materialized-views” e selezionato default come crittografia; abbiamo aggiunto un ruolo IAM adatto per l'esecuzione.
Il ruolo può essere creato utilizzando l'editor per ruoli e policy di AWS, tenendo però a mente che, una volta creato, si dovrà modificare la trust relationship con il seguente codice per abilitare il ruolo IAM, altrimenti non saremo in grado di vedere il ruolo nel selettore:
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"materializedviews.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}Qui abbiamo invece uno screenshot con i parametri utilizzati:
Una volta creata, la vista deve essere attivata per sincronizzarsi con il bucket S3; per farlo, siamo andati sia nella tabella che nella vista che avevamo creato, e abbiamo cliccato su “Attiva” nel loro pannello di dettaglio.
Dopo un paio di minuti dall'attivazione, il bucket S3 è stato riempito con i dati risultanti!
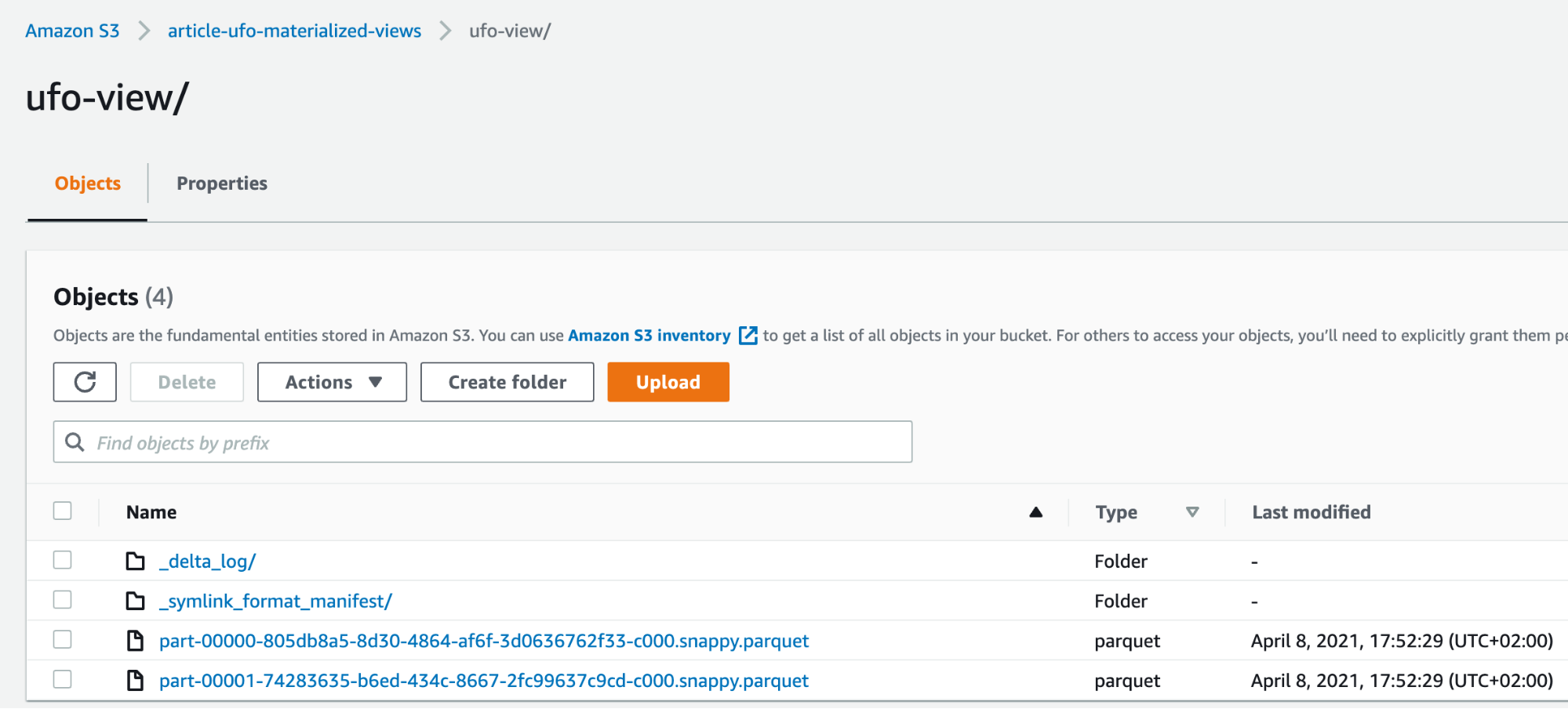
Fatto interessante: appena prima di attivare la visualizzazione, il servizio si è lamentato del fatto che alcuni campi non fossero compatibili con il target di output e ci ha dato la possibilità di modificare la visualizzazione al volo con un editor in linea, questo è quello che abbiamo fatto per castare "Latitudine" e "Longitudine" a numero intero:

I dati sono ora collegati direttamente con il nostro bucket S3, quindi qualsiasi modifica apportata alla tabella si riflette direttamente dopo alcuni secondi. Fondamentalmente è come avere un Glue Crawler che funziona su richiesta, che si accende e si spegne quando necessario, e senza intervento umano.
Volevamo dimostrare che è possibile modificare i dati ottenuti dalla tabella DynamoDB in qualsiasi momento, per questo abbiamo iniziato salvando "file parquet incompleti" come il lettore può osservare qui:
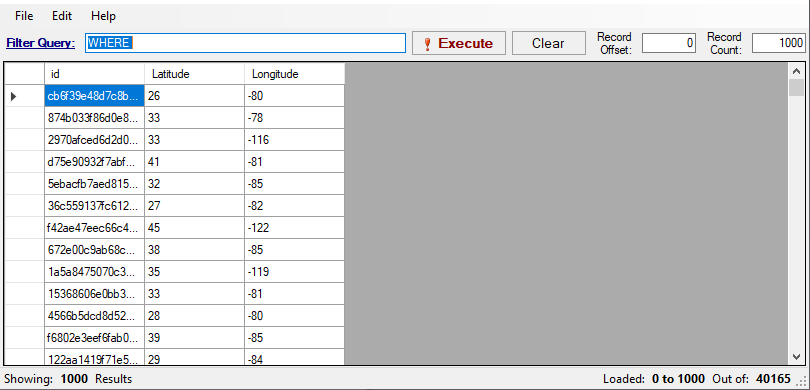
Per modificare il nostro set di dati finale dovevamo prima "disattivare" la vista materializzata. Successivamente, è stato possibile definire una nuova vista Materializzata sullo stesso target aggiungendo più colonne. Si noti inoltre che, se si dispone di più visualizzazioni dipendenti l'una dall'altra, è necessario disattivarle ed eliminarle nell'ordine corretto. Forse questa operazione diventerà meno macchinosa al momento del rilascio ufficiale.
Abbiamo modificato la definizione originale della vista materializzata aggiungendo più colonne:
SELECT id,cast(City as string),cast(State as string),cast(Shape as string),cast(Latitude as integer),cast(Longitude as integer) FROM article_ufo_sightings.article_ufo_sightings;Nonostante il processo non proprio lineare, queste operazioni hanno richiesto meno di 5 minuti e i nuovi dati sono stati presto resi disponibili nel bucket S3 corretto:
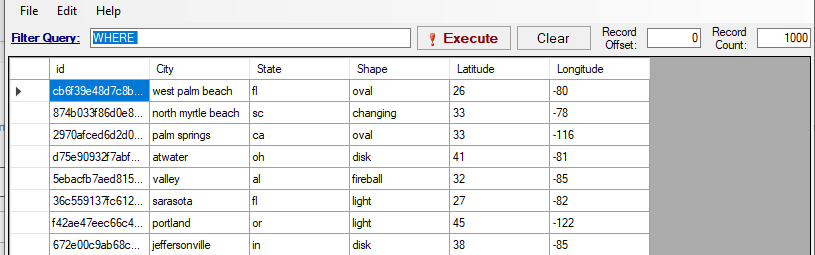
Ovviamente se le modifiche si trovano nella tabella originale e non nella vista, gli aggiornamenti sono completamente “seamless” come ci si aspetterebbe.
Un altro promemoria: essendo l'interfaccia ancora in fase di anteprima, consigliamo di evitare di lanciare molte operazioni in poco tempo, poiché abbiamo riscontrato diversi bug legati a “race condition” non ancora gestite correttamente.
Per verificare che il datasource target sia sfruttabile per lavori di machine learning, abbiamo anche preparato un semplice Jupiter Notebook di test per SageMaker, applicando alcune semplici analisi di correlazione sul data lake creato. Tutto questo si può vedere in dettaglio nel notebook. L'idea era di verificare se esiste una sorta di correlazione tra luoghi, città e avvistamenti UFO e, sulla base dei dati di esempio, provare a fare alcune semplici inferenze. Ulteriori informazioni su come utilizzare SageMaker per fare inferenza sono state trattate in questo articolo.
Siamo giunti alla fine di questo viaggio nelle meraviglie di AWS Elastic Views, quindi è il momento di riassumere ciò che abbiamo imparato finora.
Questo servizio AWS si rivela prezioso quando si tratta di lavorare con molte origini dati, soprattutto se di diversa natura, in quanto recupera e interroga tutti i dati con un linguaggio compatibile SQL (PartiQL), evitando la creazione di molti lavori ETL Glue complessi.
È perfetto in tutte quelle situazioni in cui è necessario combinare dati legacy e nuovi, poiché di solito risiedono, come da best practice, su diverse origini dati: quelle più economiche per gli accessi poco frequenti e quelle con bassa latenza per i nuovi dati.
Se vogliamo utilizzare S3 come target, diventa una soluzione adatta per job di SageMaker o anche per attività che sfruttano i servizi di AWS Managed Machine Learning.
Se ElasticSearch è il target designato, Elastic Views diventa perfetto per i workload di Business Intelligence.
AWS Elastic Views supporta gli aggiornamenti in tempo reale sui dati, con la possibilità di aggiornare anche un singolo valore per riflettere le modifiche; tutto questo utilizzando un linguaggio SQL semplice e universalmente noto, che offre funzionalità SQL per i database che non le supportano.
Potendo aggiornare un singolo campo, evita di eseguire nuovamente la scansione di tutti i dati in un'origine dati per aggiornare la destinazione scelta.
Infine, vorremmo dare un consiglio: poiché la preview attuale è ancora in una fase molto preliminare, la maggior parte delle funzionalità descritte non sono ancora disponibili completamente per una prova, quindi anche se il prodotto è già utile in diversi casi, è bene sperimentare prima di utilizzarlo per i lavori di produzione o attendere il rilascio pubblico.
Ed eccoci qui! Ci auguriamo che la lettura ti sia piaciuta e che abbia fornito utili spunti. Come sempre, sentiti libero di commentare nella sezione sottostante e contattaci per qualsiasi dubbio, domanda o idea!
Ci vediamo su #Proud2beCloudtra un paio di settimane per un'altra storia!


