VPC Lattice: yet another connectivity option or a game-changer?
12 April 2024 - 4 min. read
Damiano Giorgi
DevOps Engineer



Big Data has rapidly grown as a way to describe information obtained from heterogeneous sources when it becomes incredibly complex to manage in terms of Variety, Veracity, Value, Volume, and Velocity. Still, it can be considered the “New Gold because of the potential to generate business value.”
Without adequate governance or quality, data lakes can quickly turn into unmanageable data swamps. Data engineers know the data they need lives in these swamps, but they won't be able to find, trust, or use it without a clear data governance strategy.
A very common challenge is maintaining Governance, access control over users who operate on the Data Lake, and protecting sensitive information.
Companies need to centralize governance, access control, and a strategy backed by managed services to fine-grain control user access to data.
Dealing with these situations typically requires two approaches: manual, more flexible but complex; managed which requires your solution to fit into specific standards but in return takes away all management complexities for the developers.
This article will guide you through setting up your Data Lake with Lake Formation, showing all the challenges that must be addressed during the process with a particular eye on Security and Governance through the LF-TBAC approach.
Tag-Based Access Control, in short TBAC, is an increasingly popular way to solve these challenges, applying constraints based on tags associated with specific resources.
So, without further ado, let’s dig in!
Tag-based access control allows administrators of IAM-enabled resources to create access policies based on existing tags associated with eligible resources.
Cloud providers manage permissions of both users and applications with policies, documents with rules that reference resources. By applying tags to those resources is possible to define simple and effective allow/deny conditions.
Using access management tags may reduce the number of access policies needed within a cloud account while also providing a simplified way to grant access to a heterogeneous group of resources.
S3, like most AWS services, leverages the IAM principals for access management, meaning that it is possible to define which parts of a bucket (files and folders/prefixes) a single IAM principal can read/write; however is not possible to further restrict IAM access to specific parts of an object, nor to certain data segments stored inside objects.
For example, let’s assume that our application data is stored as a collection of parquet files divided per country in different folders.
It is possible to constrain a user to access only the users belonging to a given country. Still, there is no way to prevent them from reading the anagraphic information (e.g., username and address) stored as columns in the parquet.
The only way to prevent users from accessing sensitive information would be to encrypt the columns before writing the files to S3, which can be slow, cumbersome, and open a whole new ‘can of worm’ regarding key storage, sharing, and eventually key decommissioning.
Furthermore, giving access to external entities using IAM principals is often a non-trivial problem on its own.
Luckily, AWS offers a battery included solution to the S3 Data Lake permission problem: enters AWS Lake Formation!
AWS Lake Formation is a fully managed service that simplifies building, securing, and managing data lakes, automating many of the complex manual steps required to create them.
Lake Formation also provides its own permissions model, which is what we want to explore in detail, that augments the classical AWS IAM permissions model.
This centrally defined permissions model enables fine-grained access to data stored in data lakes through a simple grant/revoke mechanism.
So, by leveraging the power of Lake Formation, we would like to demonstrate, with a simple solution, how to address the aforementioned S3 challenges; let’s continue!
To accompany the reader in understanding why AWS Lake Formation can be a good choice in dealing with the complexities of managing a DataLake, we have prepared a simple tutorial on how to migrate heterogeneous data.
From legacy on-prem databases into S3 while also creating a Lake Formation catalog to deal with data cleansing, permissions, and further operations.
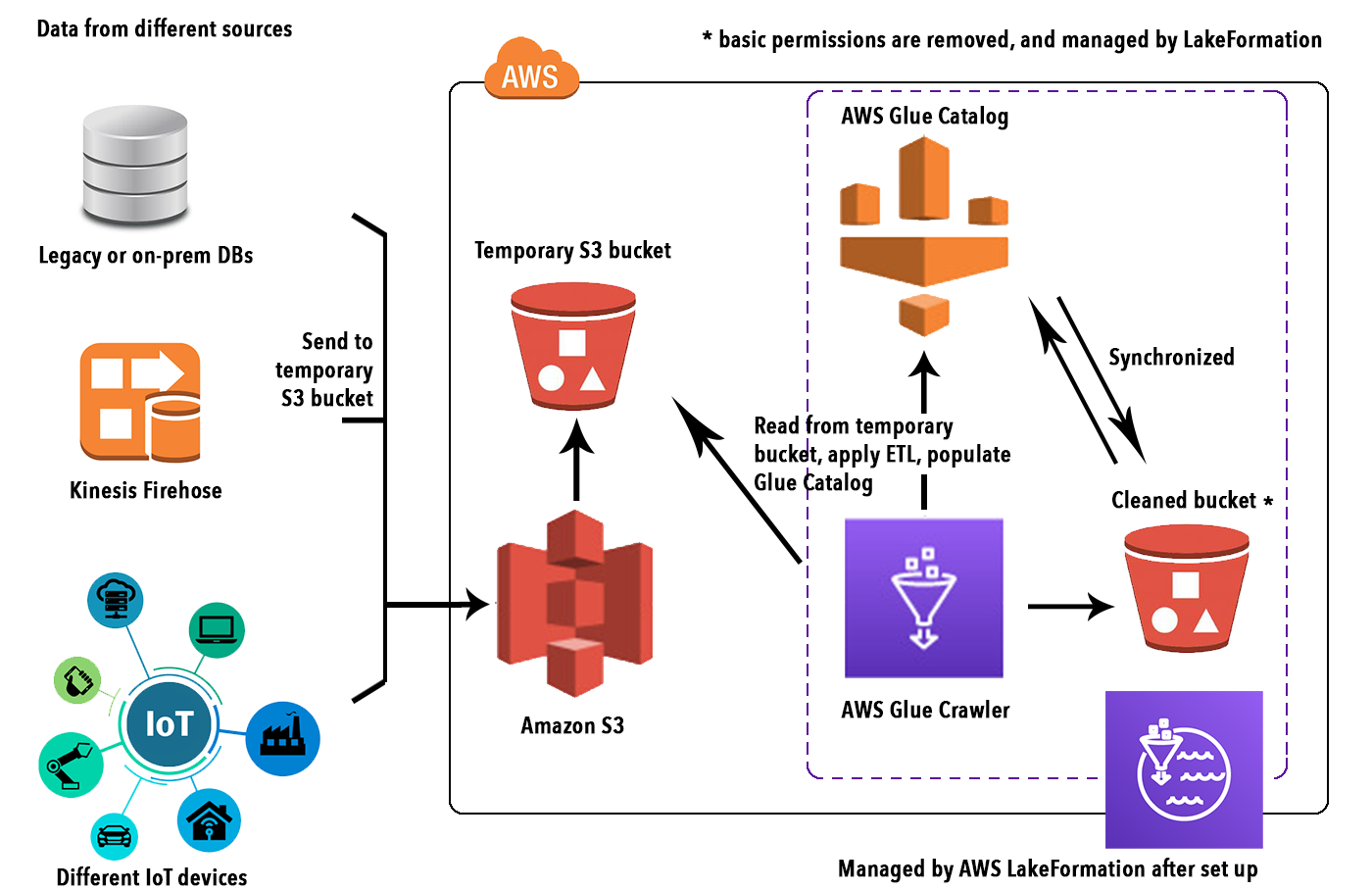
The first step for creating a Data Lake is obviously to fetch, transform and insert the data. In this simple example, we used a mocked users dataset from a MySQL database. AWS glue is the natural way to connect to the heterogeneous data source, infer their schema import and transform the data and finally write them on S3 as we explained in detail here.
After the data is loaded in a temporary S3 bucket, you need to create a Database in Lake Formation to connect to a Glue Crawler and run it on your S3 prefix to populate a Glue Catalog for your data.
Just go to the AWS Lake Formation console, in the Databases page under the Data catalog tab, and fill in a Database name and your S3 path.
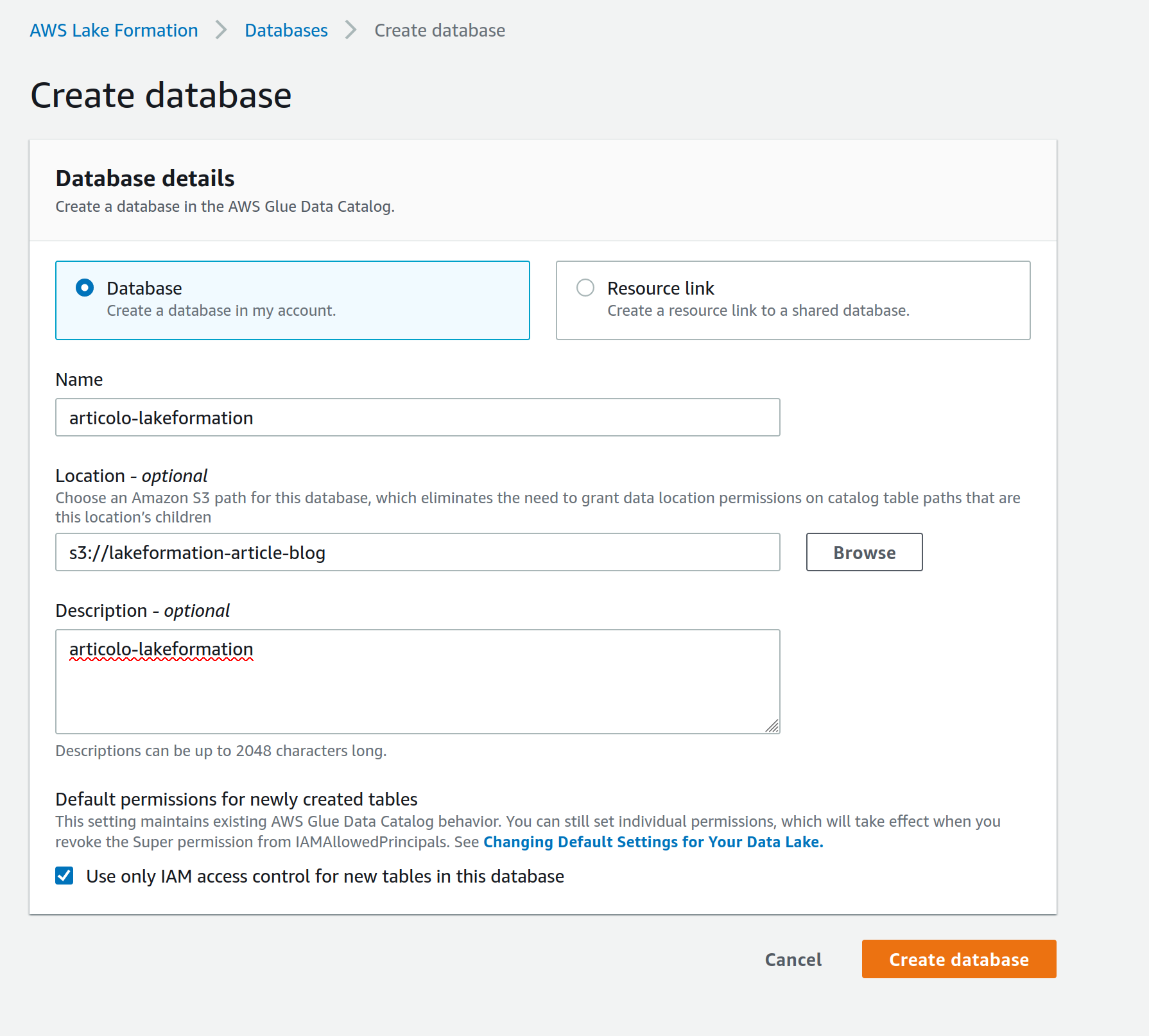
Note: creating a database from Lake Formation assures correct permissions are associated with it, we could have done the same thing from AWS Glue but we would have needed extra effort to modify permissions for the next steps.
After the database is created, we need the Glue Catalog, which is a metastore containing the schema (schema-on-read) of your data saved in S3 (usually as parquet files).
Having a Glue Schema is necessary to set up the AWS Lake Formation access layer in front of your S3 Data Lake. To make it, just create a Crawler and link it to the same S3 path as the Database, and set that DB as the crawler output.
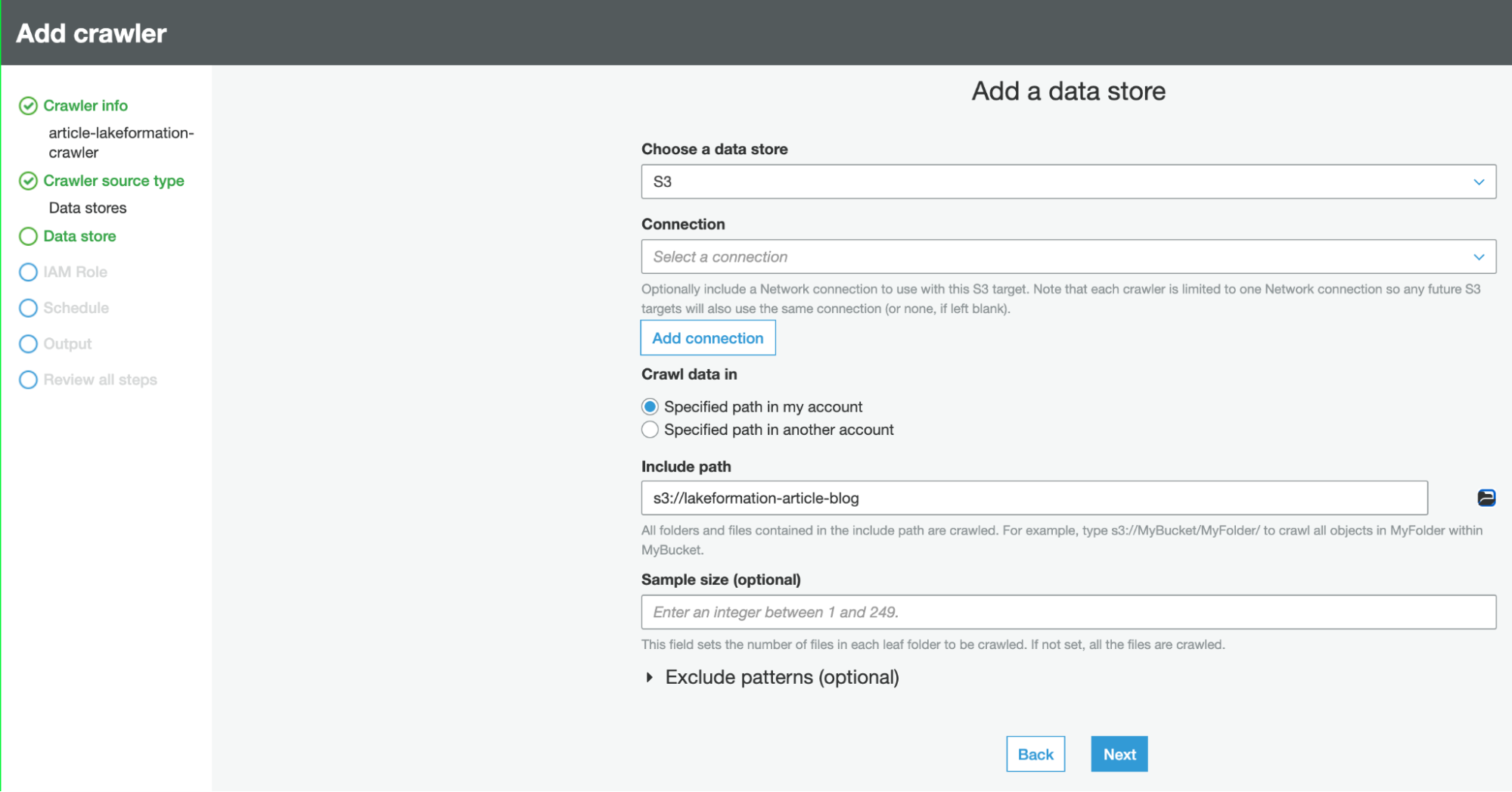
In order to use the Crawler, an IAM role is necessary, but luckily AWS has a step for that in the Crawler creation wizard:

Once the Crawler is created, and data is imported into the catalog, we are ready for the next step.
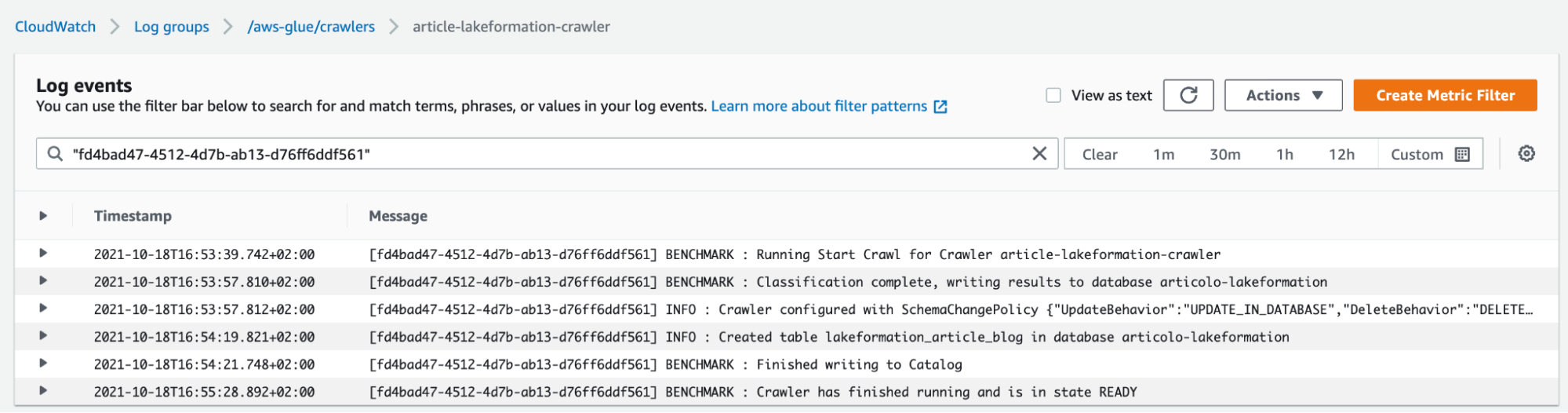
By having a Glue Data catalog in place, it is time to set up Lake Formation to finally manage user access permissions.
In order to do so, let’s start by going to the Lake Formation dashboard and removing the usual S3 access permissions.
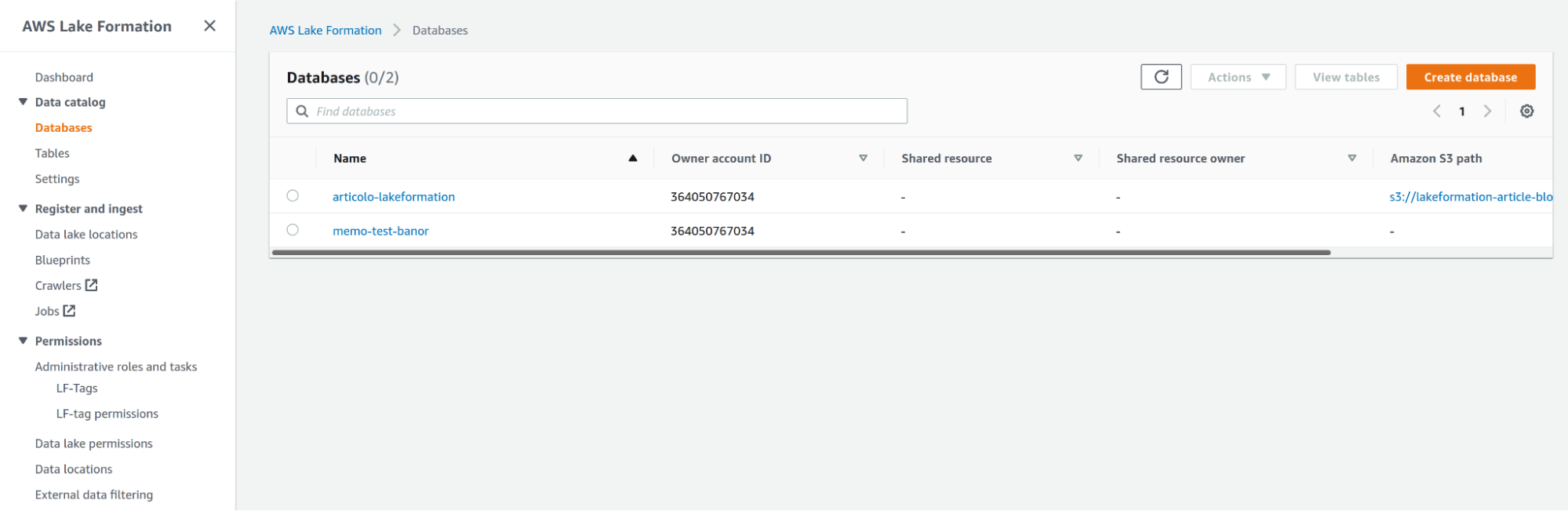
So we can go to Data Catalog Settings and uncheck Use only IAM access control for new databases and Use only IAM access control for new tables in new databases.
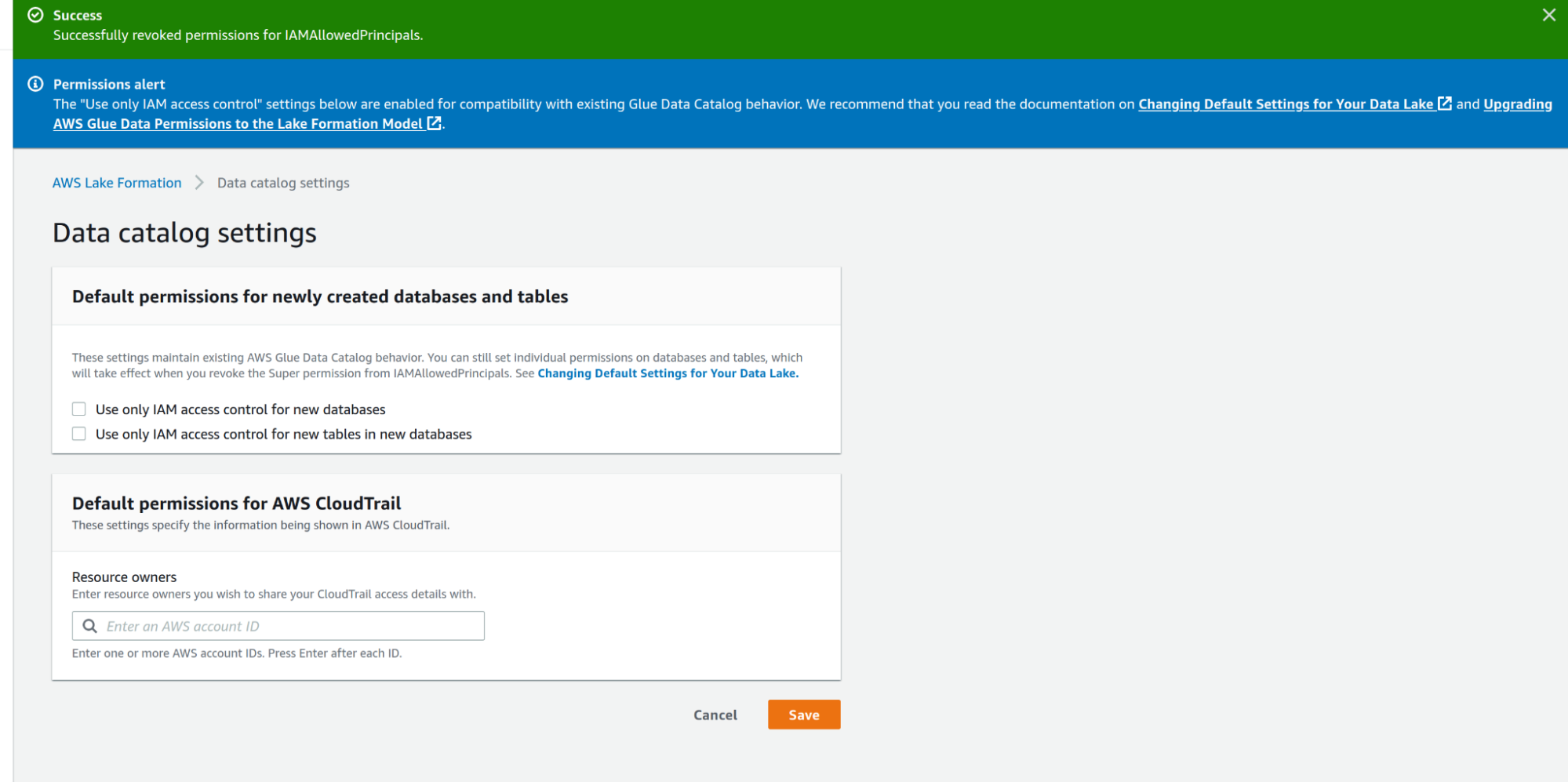
By default, access to Data Catalog resources and Amazon S3 locations are controlled solely by AWS Identity and Access Management (IAM) policies, unchecking the values allows Individual Lake Formation permissions to take effect.
Once access responsibilities are delegated to Lake Formation, we can remove the access for the standard IAMAllowedPrincipals IAM group, in the data lake Permissions tab, select the permission of the IAM group and click Revoke.
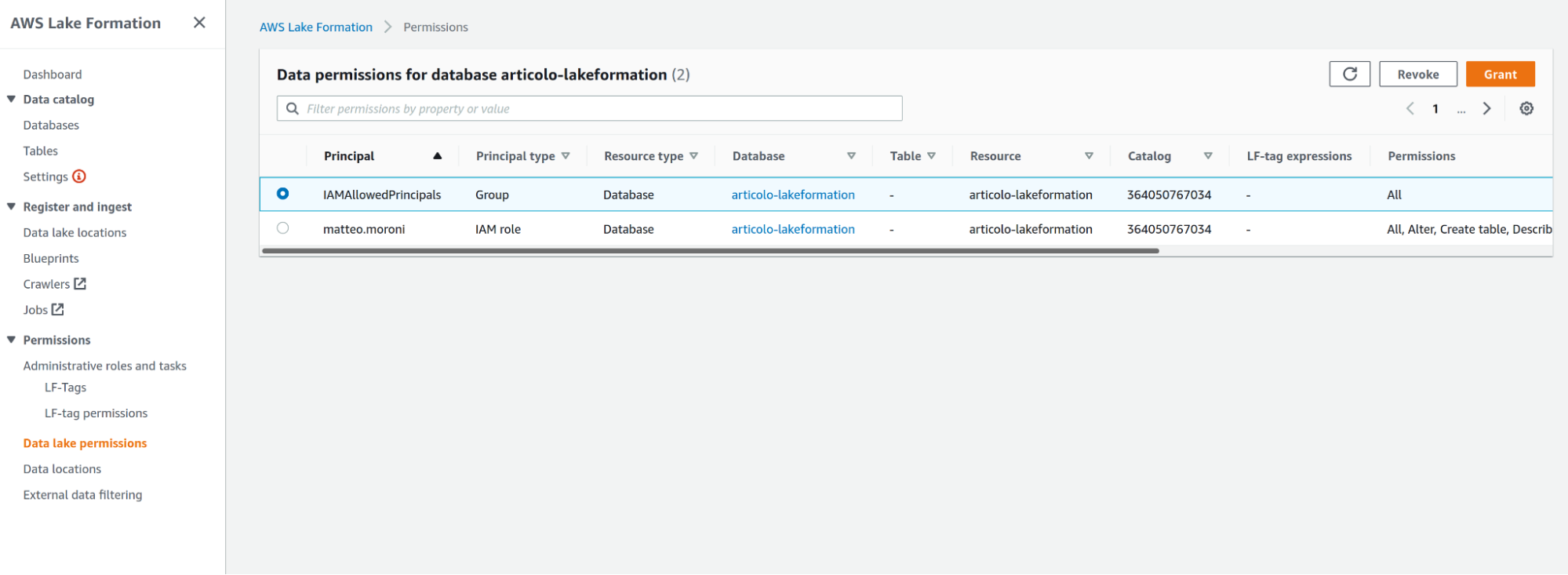
The user creating the DataLake will also be listed in this section with admin privileges, if you want that user to retain access to the data you can leave the permission as they are, otherwise you can either revoke the permission to the user/role or restrict them.
Note: if you need to add a Data lake administrator principal, you can do so by going to the Administrative roles and tasks and adding a Data lake admin.
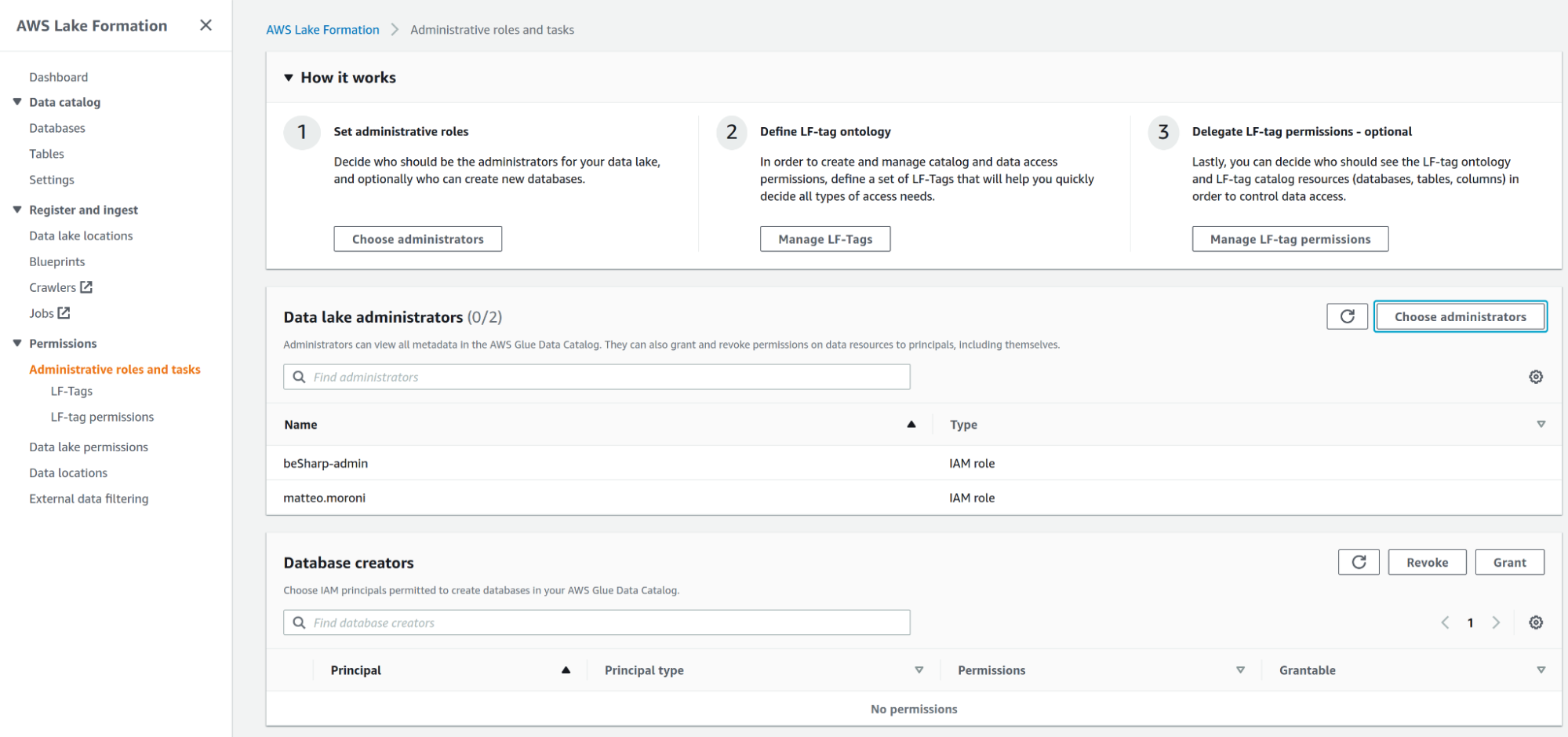
Once all these steps are completed, it is time to start defining Lake Formation tags (LF-Tags from now on), which will be used to restrict access to the data lake.
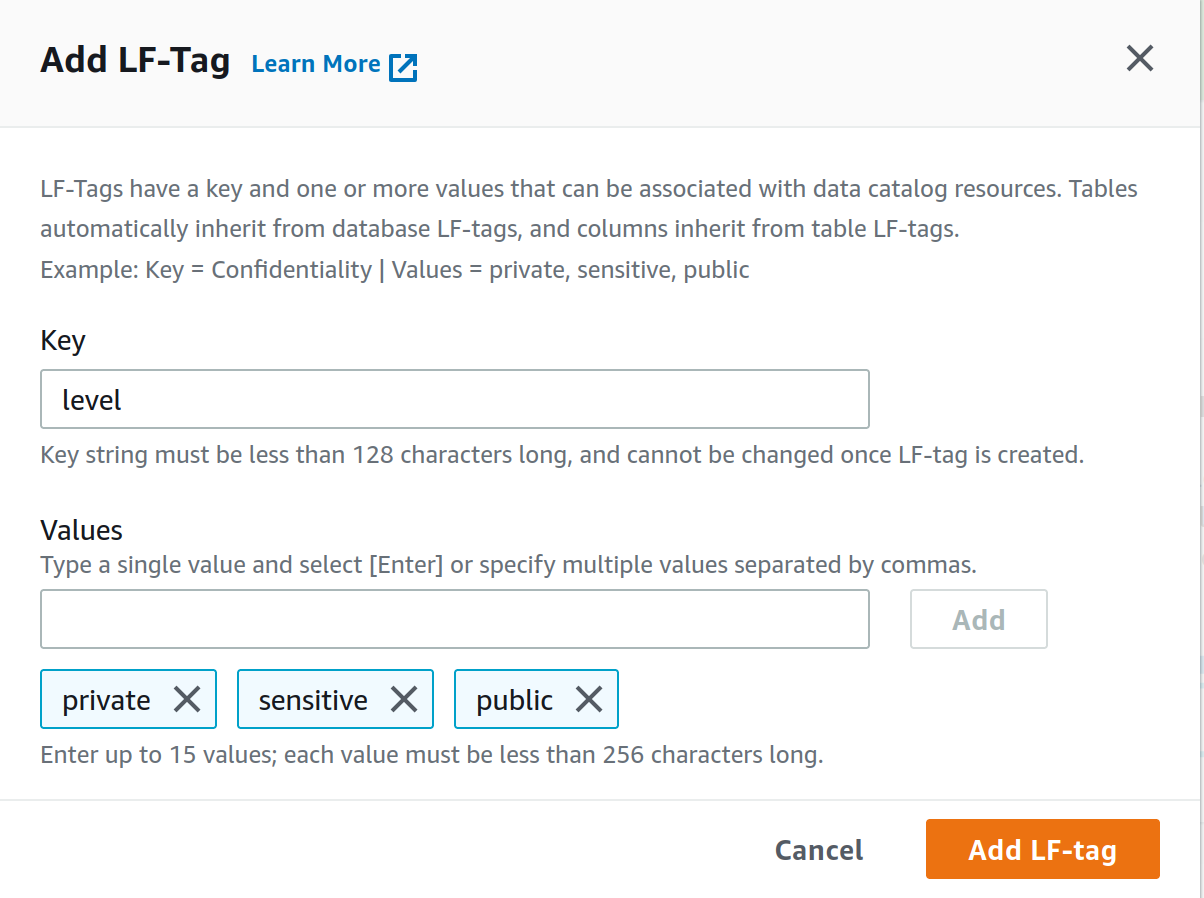
From the LF-Tags page under the Permissions tab create a new LF-Tag and for key use level and add private, sensitive, and public as value separated by comma just like in the figure. Click Add LF-tag.
Now once created, how can we use these tags to enforce access control? First of all, let’s go to the database section and select our database, created at the beginning of the tutorial. In database actions, you can select the tag you’ve created and the permission level.
Usually, we leave the database access open and restrict permissions on a per table and fields basis, but this is different for each database. In our example, we assign the level public to the whole example database.
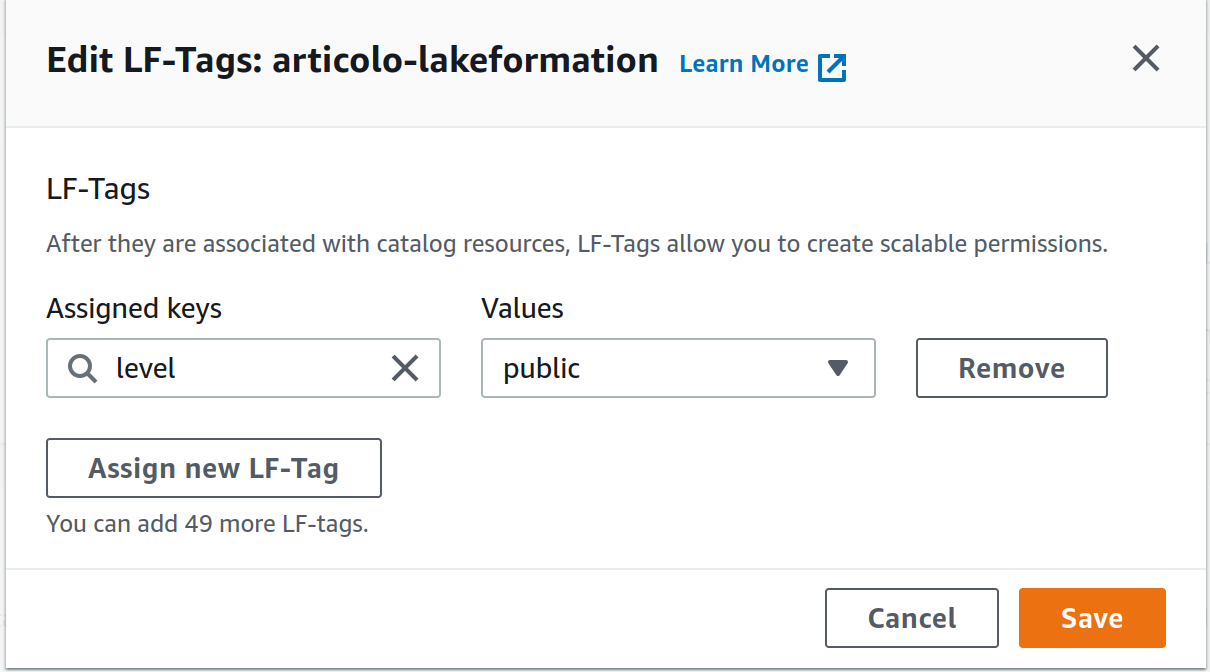
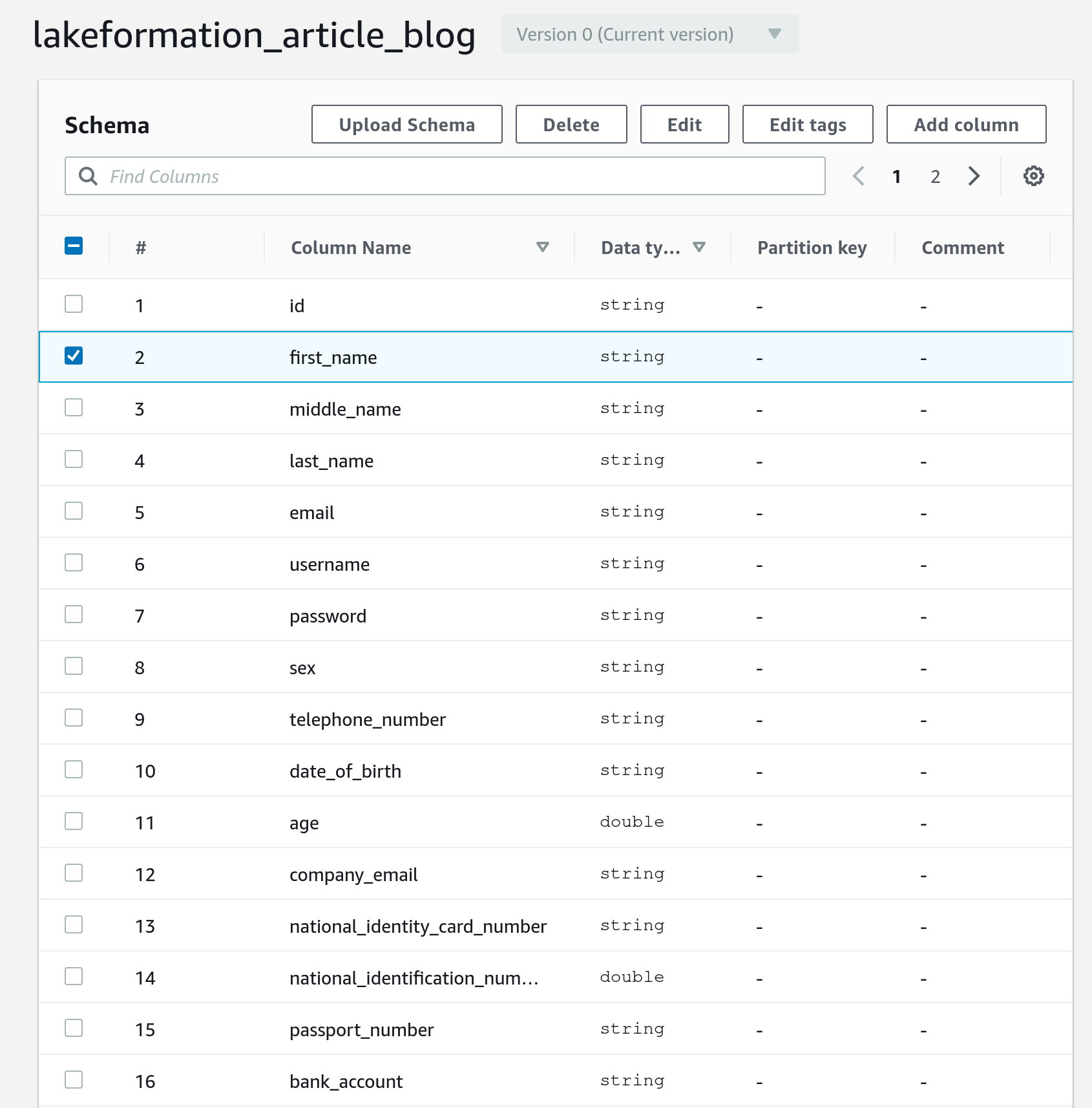
Now if we want to restrict access to the columns in the user table containing personal info, we can go to the table to modify, select the column and change its LF-tag from public to private (see figures).
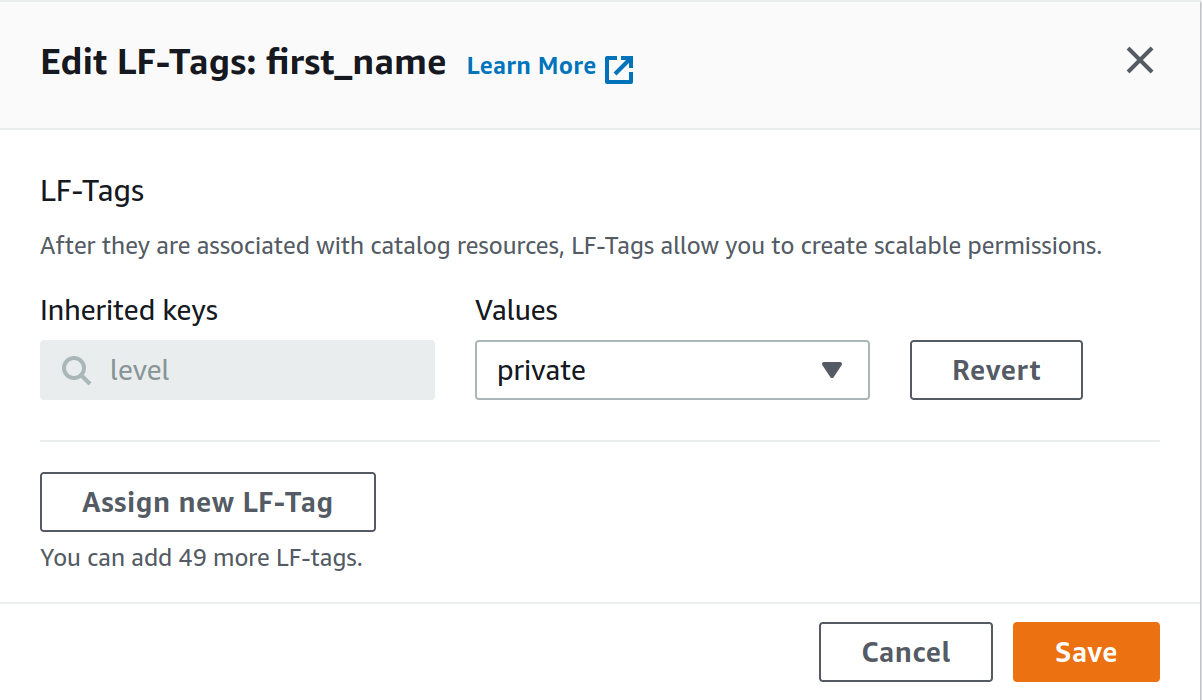
Now we just need to define which IAM principals (i.e, our test user) will have access to a given LF-Tag. To do so, let’s go to Data lake permissions and grant permissions to an IAM user/role/group to access resources tagged with a given LF-Tag.
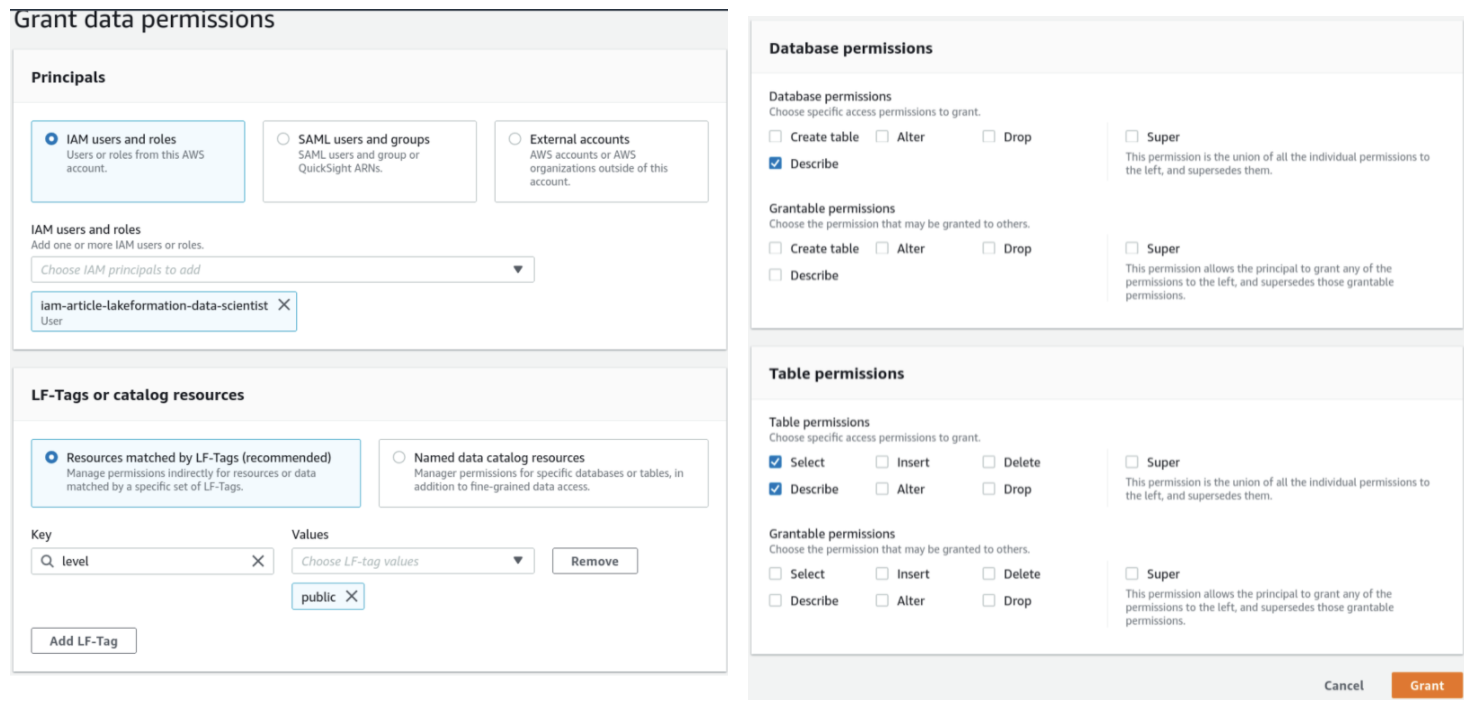
This example shows how to give a user access to all the resources tagged with “level”: “public”.
This user will thus be able to see all our databases except for the personal data tagged as private. Another user may have access to both public and private information, just add the private level in the LF-Tag section or modify columns tags according to your needs.
We can now query the database table using our test user which, based on our set of permissions, is not able to see the first_name column (which is tagged as private).
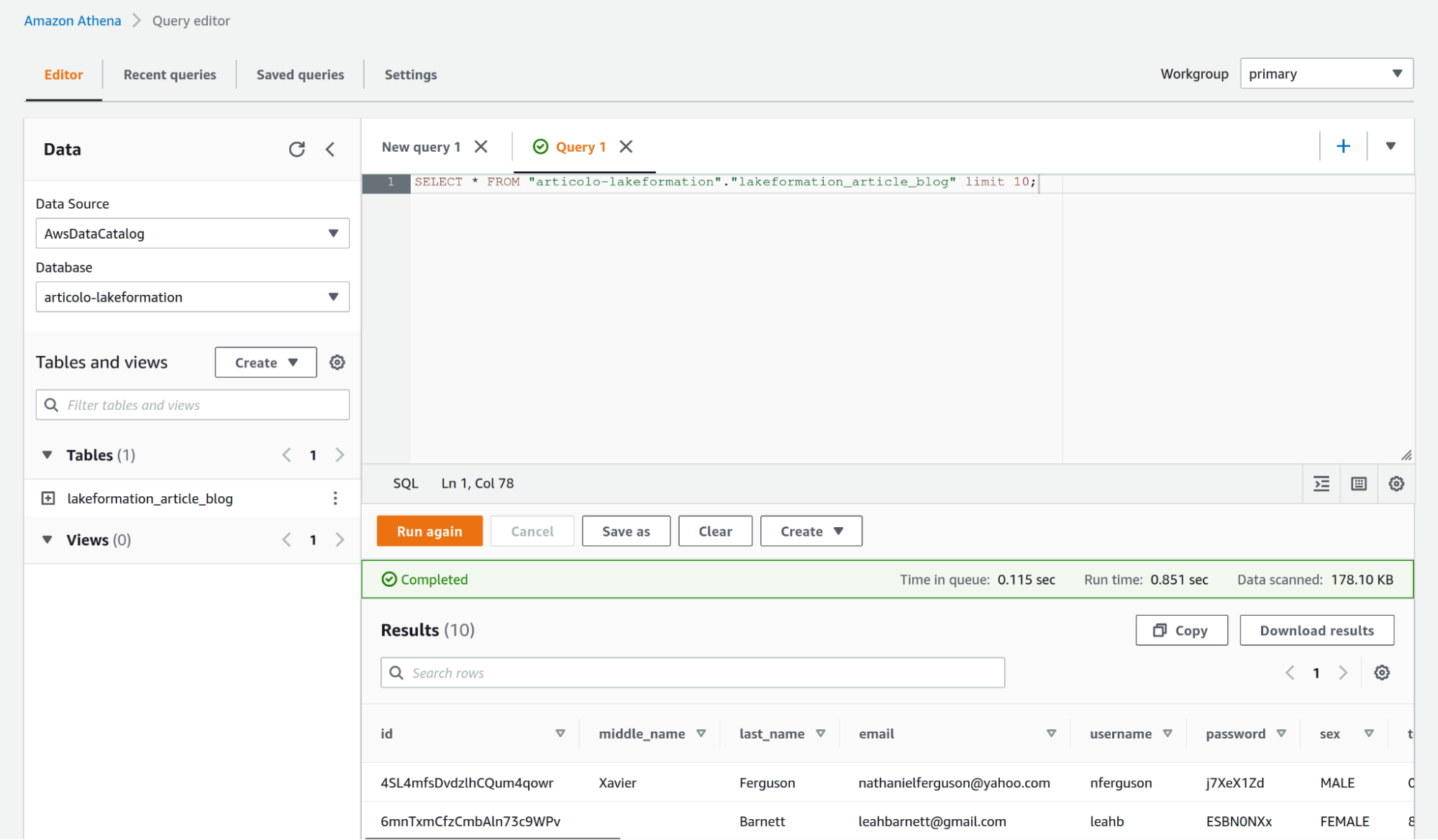
As shown in the figure we have successfully managed to deny our test user the right to see a “sensible” column of our choice.
We would like to encourage the user to experiment in adding or removing also describe and select options from the LF-Tag permissions in the Data Lake section to see that we can also deny listing both database and tables.
Note: as of Nov 3, 2021: to enhance security, AWS Lake Formation also added support for managed VPC endpoints via AWS PrivateLink to access a data lake in a Virtual Private Cloud.
Lake Formation is still a young service, so there is much room for improvement. AWS is constantly working on increasing features for its services, and Lake Formation is no exception.
AWS Lake Formation already allows setting access policies to hide data, such as a column with sensitive information, from users who do not have permission to view that data.
Row-level security will add up to that by allowing to set row-level policies in addition to column-level policies.
An example could be setting a policy that gives a data scientist access to only the experiment data marked with a specific id.
Another interesting aspect would be to share the same Data Lake for different datasets to reduce costs and management efforts.
In this article, we have seen how we can leverage the power of AWS Services for Storage and Data Analytics to tackle the challenge imposed by Big Data, in particular how to manage access, permissions, and governance.
We have shown that AWS Glue crawlers can effectively retrieve unstructured data from temporary repositories, being them databases like RDS or on-premises, or object storages like S3, and obtain a schema to populate a Glue Catalog.
We have seen that starting from S3 and a metadata store, it is possible to create a Lake Formation Catalog on top of S3, entirely managed by AWS, to drastically reduce the management effort to set up and administrate a Data lake.
We have briefly seen what is a Tag-Based Access Control (TBAC) methodology and how can be effectively used to manage access and permissions.
We have shown that AWS Lake Formation can apply IAM policies and TBAC rules to give or restrain access to users and groups even on a per-column/row basis. We demonstrated that with Lake Formation and AWS Glue, we could obscure sensitive data to specific principals.
We have described LF-Tags in detail, with a simple tutorial. Finally, We have talked about Row-Level Security.
To conclude, we can say that for challenges regarding Big Data and proper storage solutions, with an eye for security and governance matters, there are always two possible choices to make: DIY or opt for a managed solution.
In this article, we chose a managed solution to show all the benefits of a more rigid approach to the problem. Despite being less flexible to adaptation, it offers a service more adherent to best practices and less burden in administration and governance.
As always, feel free to comment in the section below, and reach us for any doubt, question or idea!
See you on Proud2beCloud in a couple of weeks for a new story!


