VPC Lattice: yet another connectivity option or a game-changer?
12 April 2024 - 4 min. read
Damiano Giorgi
DevOps Engineer


 We are in the middle of the serverless age, in a moment where the advantages of this approach become more and more evident.One of the advantages that contributed the most to the rise of the serverless paradigm is certainly the promise of significant economic advantages. But are you really saving money? And: are you taking full advantage of the serverless paradigm?
We are in the middle of the serverless age, in a moment where the advantages of this approach become more and more evident.One of the advantages that contributed the most to the rise of the serverless paradigm is certainly the promise of significant economic advantages. But are you really saving money? And: are you taking full advantage of the serverless paradigm?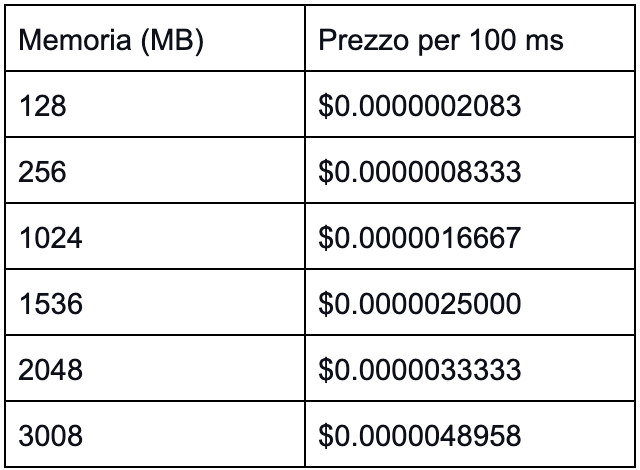 The following facts can thus be deduced from the pricing model:
The following facts can thus be deduced from the pricing model: These are only some of the tricks which can be used to optimize the costs of a serverless application, obviously, there are many more particular cases and specific scenarios that can benefit from the most disparate infrastructure customizations.In general, on AWS it is important to take into consideration the pricing model of each service and build both the infrastructure and the application in order to take advantage of them rather than pay more to use the services in a non-optimal way.Do not miss the next articles for further tips on the subject!
These are only some of the tricks which can be used to optimize the costs of a serverless application, obviously, there are many more particular cases and specific scenarios that can benefit from the most disparate infrastructure customizations.In general, on AWS it is important to take into consideration the pricing model of each service and build both the infrastructure and the application in order to take advantage of them rather than pay more to use the services in a non-optimal way.Do not miss the next articles for further tips on the subject! 

